
AI Data Collection for Training: A Practical Framework for Product and Marketing Teams
Updated on
Published on
AI data collection is the foundational step for any machine learning project. Even the most sophisticated algorithms cannot work without a constant flow of appropriate inputs. This information is required by development groups to validate features. It is used by marketing departments to learn about audience behavior. However, it is not always easy to collect this.
Poor quality ruins projects. Poor data quality costs organizations about 12.9 million dollars a year. This figure demonstrates that the collection technique is as important as the volume.
This article presents a realistic model of intelligence collection. It includes sources, infrastructure, and validation.

The Role of AI Data Collection in Commercial Success
Why are certain AI solutions intuitive and others fail? The solution is normally in the training content. AI data collection allows developers to feed models with real-world examples. This assists the system in identifying patterns.
In the case of a marketing team, this could be the analysis of social media sentiment. In the case of a manager, it may include the review of user interaction logs.
The Main Advantages of Structured Collection
- Precision: Models are trained on a variety of examples.
- Relevance: Information is a reflection of the current market trends.
- Speed: Automated processes minimize manual efforts.
Note: The quality of a model is as good as its input. The output will be faulty if you feed it biased or incomplete records.
Sourcing and AI Data Scraping Methods
What is the source of intelligence? There are three primary sources that companies tend to use. Each has pros and cons.
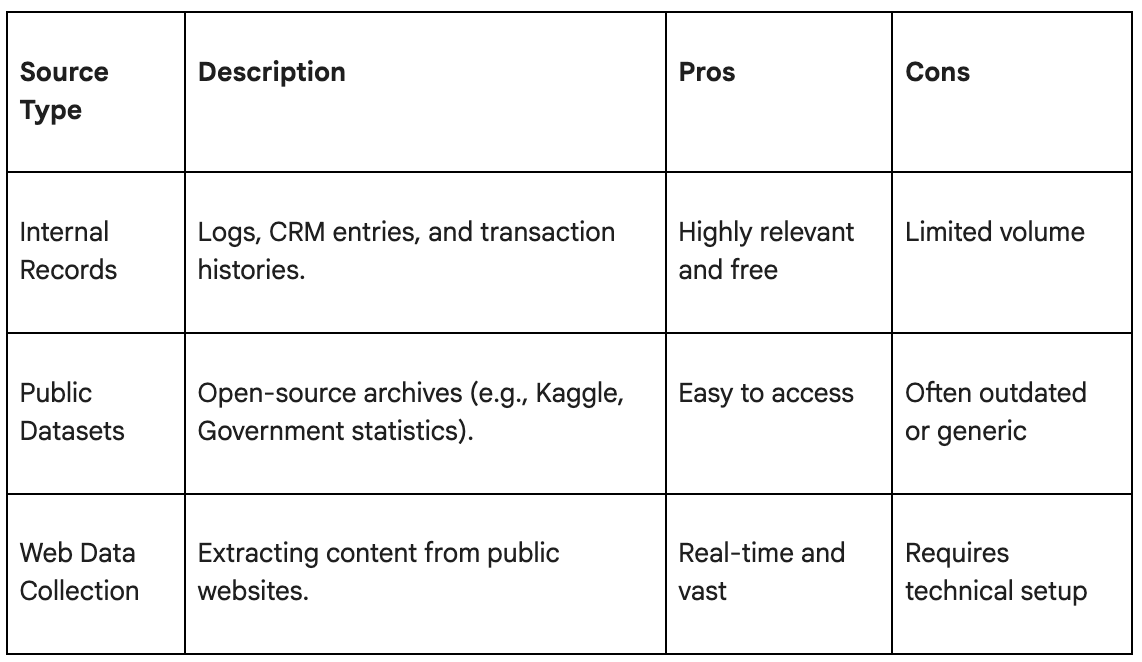
AI scraping is often the most effective way to build a custom repository. This is done by visiting websites with the help of bots and scraping certain information. It can be used to track the prices of competitors or consolidate news.
But scraping needs to be maintained. Sites are dynamic in their layouts. This breaks the scrapers. To keep the pipeline running, staff have to update their scripts on a regular basis.
Infrastructure for Automated Data Gathering
The establishment of a dependable pipeline is a technical issue. You cannot just issue a million requests to a server with one office IP. This looks suspicious. Such traffic will be blocked by most of the platforms to safeguard their resources.
To scale automated gathering, engineers use a distributed infrastructure. This is usually a chain of middlemen.
Traffic Management Using Proxies
To extract information in various areas, you must appear as a local user. A script in Berlin that attempts to scrape prices from a New York retailer may encounter the wrong currency. Or it may be shut off completely.
This is where residential proxies come in handy. They enable your scraper to send requests to actual devices in designated places. This assists the analysts in viewing the web as their users do. It also distributes the load.
Using proxy servers for AI scraping helps maintain a high success rate. This minimizes the possibility of being halted by mere rate limits.
Residential IP Rotation Techniques
Static IPs are easy to spot. If one IP address demands 5,000 pages within one minute, it is flagged.
Residential IP rotation solves this. The system allocates a new IP to each request or each session. This replicates the actions of thousands of individual users as opposed to a single bot. It keeps the pipeline stable.
Building and Managing Training Datasets
When the raw input is received, the job is not finished. Raw HTML or JSON logs are untidy. They have redundancies, inaccuracies, and extraneous noise. You need to convert this into clean training datasets.
Structured and Unstructured Data
There are two types of information:
- Structured: Tabular (SQL databases, CSVs). Easy to use.
- Unstructured: Text, images, videos. Harder to process.
Machine learning datasets often require a mix of both. As an illustration, an e-commerce AI requires structured price values and unstructured descriptions of items.
Data Quality and Validation
Check the feed material for a model before feeding it.
- Deduplication: Eliminate duplicate entries.
- Normalization: Standardize formats (e.g., all dates in YYYY-MM-DD).
- Outlier Detection: Eliminate values that do not make sense (e.g., a user age of 200).
Strategy for Product Team Analytics
Efforts in collection should be based on a strategy. Do not gather everything. Gather what you need.
Analytics should focus on metrics that drive decisions. If the goal is to enhance search relevance, monitor unsuccessful search queries. If the objective is to reduce churn, consider the length of review sessions.
Marketing Strategy Integration
Marketing departments should be aware of whom to target. Marketing data strategy relies on external signals. This encompasses trending topics, competitor ad spend, and keyword volume.
This intelligence can be integrated into a central dashboard to assist the workforce move at a fast pace. They are able to identify a trend in the morning and roll out a campaign by noon.

Ethics and Regional Data Sampling
The collection is responsible. Privacy regulations such as GDPR and CCPA are very strict. Ethical data collection means respecting these boundaries.
- Public Info Only: Scrape only publicly available content that does not require a login.
- Respect Robots.txt: Does a site specifically forbid scrapers?
- Rate Limiting: Do not flood a target server. Be polite.
Regional sampling must also be fair. If you harvest exclusively in the US, your AI will be skewed against other areas. Ensure that your set is a reflection of your whole user base.
Establishing Large-Scale Data Pipelines
Enterprise requirements cannot be satisfied with ad-hoc scripts. You need large-scale pipelines. These are systems that run 24/7. They are automated in extraction, cleaning, and storage.
AI data collection at this level requires robust error handling. If a source fails, the system must reattempt or notify an engineer. It is not supposed to crash the whole database.
Summary of the Framework
- State the Objective: What is the problem that the AI is solving?
- Select Sources: Where is the information?
- Construct Infrastructure: Access content using proxies and rotation.
- Check: Clean the records strictly.
- Monitor: Maintain a smooth flow of the pipeline.
This cycle is essential to successful AI product launches. It works, and it pays off in model performance.
.png "Best Branding Agencies in Toronto (2026)")
%20(1).png "10 Best Web Design Companies in Toronto (2026)")






